Neural Computing and Applications ( IF 4.5 ) Pub Date : 2023-10-06 , DOI: 10.1007/s00521-023-09021-x Ruijun Li , Weihua Li , Yi Yang , Hanyu Wei , Jianhua Jiang , Quan Bai
|
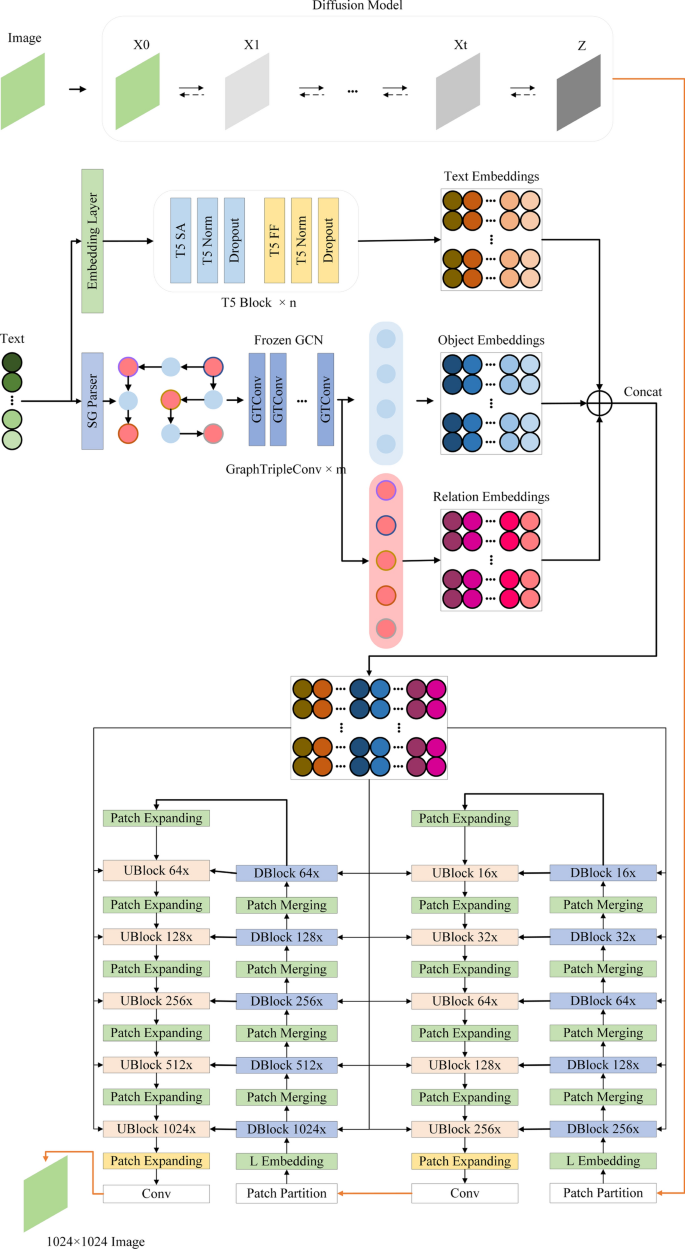
Recently, diffusion models have been proven to perform remarkably well in text-to-image synthesis tasks in a number of studies, immediately presenting new study opportunities for image generation. Google’s Imagen follows this research trend and outperforms DALLE2 as the best model for text-to-image generation. However, Imagen merely uses a T5 language model for text processing, which cannot ensure learning the semantic information of the text. Furthermore, the Efficient UNet leveraged by Imagen is not the best choice in image processing. To address these issues, we propose the Swinv2-Imagen, a novel text-to-image diffusion model based on a Hierarchical Visual Transformer and a Scene Graph incorporating a semantic layout. In the proposed model, the feature vectors of entities and relationships are extracted and involved in the diffusion model, effectively improving the quality of generated images. On top of that, we also introduce a Swin-Transformer-based UNet architecture, called Swinv2-Unet, which can address the problems stemming from the CNN convolution operations. Extensive experiments are conducted to evaluate the performance of the proposed model by using three real-world datasets, i.e. MSCOCO, CUB and MM-CelebA-HQ. The experimental results show that the proposed Swinv2-Imagen model outperforms several popular state-of-the-art methods.
中文翻译:
Swinv2-Imagen:用于文本到图像生成的分层视觉变换器扩散模型
最近,多项研究已证明扩散模型在文本到图像合成任务中表现非常出色,立即为图像生成提供了新的研究机会。Google 的 Imagen 遵循了这一研究趋势,并且优于 DALLE2,成为文本到图像生成的最佳模型。然而Imagen仅仅使用T5语言模型进行文本处理,并不能保证学习到文本的语义信息。此外,Imagen 利用的 Efficient UNet 并不是图像处理的最佳选择。为了解决这些问题,我们提出了 Swinv2-Imagen,这是一种基于分层视觉转换器和包含语义布局的场景图的新型文本到图像扩散模型。在所提出的模型中,提取实体和关系的特征向量并参与扩散模型,有效提高生成图像的质量。除此之外,我们还引入了一种基于 Swin-Transformer 的 UNet 架构,称为 Swinv2-Unet,它可以解决 CNN 卷积运算带来的问题。通过使用三个真实世界数据集(即 MSCOCO、CUB 和 MM-CelebA-HQ)进行了大量实验来评估所提出模型的性能。实验结果表明,所提出的 Swinv2-Imagen 模型优于几种流行的最先进方法。MSCOCO、CUB 和 MM-CelebA-HQ。实验结果表明,所提出的 Swinv2-Imagen 模型优于几种流行的最先进方法。MSCOCO、CUB 和 MM-CelebA-HQ。实验结果表明,所提出的 Swinv2-Imagen 模型优于几种流行的最先进方法。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号