当前位置:
X-MOL 学术
›
WIREs Data Mining Knowl. Discov.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Pre-trained language models: What do they know?
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2023-09-21 , DOI: 10.1002/widm.1518 Nuno Guimarães 1, 2 , Ricardo Campos 1, 3, 4 , Alípio Jorge 1, 2
WIREs Data Mining and Knowledge Discovery ( IF 6.4 ) Pub Date : 2023-09-21 , DOI: 10.1002/widm.1518 Nuno Guimarães 1, 2 , Ricardo Campos 1, 3, 4 , Alípio Jorge 1, 2
Affiliation
|
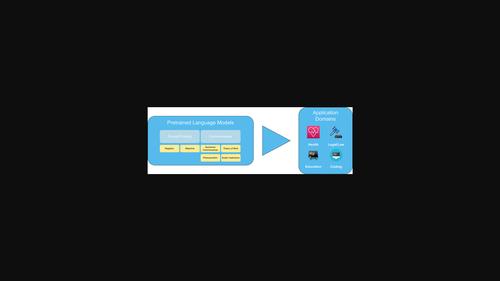
Large language models (LLMs) have substantially pushed artificial intelligence (AI) research and applications in the last few years. They are currently able to achieve high effectiveness in different natural language processing (NLP) tasks, such as machine translation, named entity recognition, text classification, question answering, or text summarization. Recently, significant attention has been drawn to OpenAI's GPT models' capabilities and extremely accessible interface. LLMs are nowadays routinely used and studied for downstream tasks and specific applications with great success, pushing forward the state of the art in almost all of them. However, they also exhibit impressive inference capabilities when used off the shelf without further training. In this paper, we aim to study the behavior of pre-trained language models (PLMs) in some inference tasks they were not initially trained for. Therefore, we focus our attention on very recent research works related to the inference capabilities of PLMs in some selected tasks such as factual probing and common-sense reasoning. We highlight relevant achievements made by these models, as well as some of their current limitations that open opportunities for further research.
中文翻译:

预训练的语言模型:它们知道什么?
过去几年,大型语言模型(LLM)极大地推动了人工智能(AI)的研究和应用。他们目前能够在不同的自然语言处理(NLP)任务中实现高效,例如机器翻译、命名实体识别、文本分类、问答或文本摘要。最近,OpenAI 的 GPT 模型的功能和极其易于访问的界面引起了极大的关注。如今,法学硕士在下游任务和特定应用中得到了常规使用和研究,并取得了巨大成功,推动了几乎所有领域的最新技术发展。然而,在未经进一步培训的现成使用时,它们也表现出令人印象深刻的推理能力。在本文中,我们的目标是研究预训练语言模型(PLM)在一些最初未训练的推理任务中的行为。因此,我们将注意力集中在与 PLM 在某些选定任务(例如事实探测和常识推理)中的推理能力相关的最新研究工作上。我们强调这些模型取得的相关成就,以及它们当前的一些局限性,为进一步研究提供了机会。
更新日期:2023-09-21
中文翻译:
预训练的语言模型:它们知道什么?
过去几年,大型语言模型(LLM)极大地推动了人工智能(AI)的研究和应用。他们目前能够在不同的自然语言处理(NLP)任务中实现高效,例如机器翻译、命名实体识别、文本分类、问答或文本摘要。最近,OpenAI 的 GPT 模型的功能和极其易于访问的界面引起了极大的关注。如今,法学硕士在下游任务和特定应用中得到了常规使用和研究,并取得了巨大成功,推动了几乎所有领域的最新技术发展。然而,在未经进一步培训的现成使用时,它们也表现出令人印象深刻的推理能力。在本文中,我们的目标是研究预训练语言模型(PLM)在一些最初未训练的推理任务中的行为。因此,我们将注意力集中在与 PLM 在某些选定任务(例如事实探测和常识推理)中的推理能力相关的最新研究工作上。我们强调这些模型取得的相关成就,以及它们当前的一些局限性,为进一步研究提供了机会。





























 京公网安备 11010802027423号
京公网安备 11010802027423号