当前位置:
X-MOL 学术
›
Lang. Resour. Eval.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
集成机器学习在阿拉伯语网络欺凌和攻击性语言检测方面的性能比较
Language Resources and Evaluation ( IF 1.7 ) Pub Date : 2023-08-13 , DOI: 10.1007/s10579-023-09683-y Marwa Khairy , Tarek M. Mahmoud , Ahmed Omar , Tarek Abd El-Hafeez

"点击查看英文标题和摘要"
更新日期:2023-08-14
Language Resources and Evaluation ( IF 1.7 ) Pub Date : 2023-08-13 , DOI: 10.1007/s10579-023-09683-y Marwa Khairy , Tarek M. Mahmoud , Ahmed Omar , Tarek Abd El-Hafeez
|
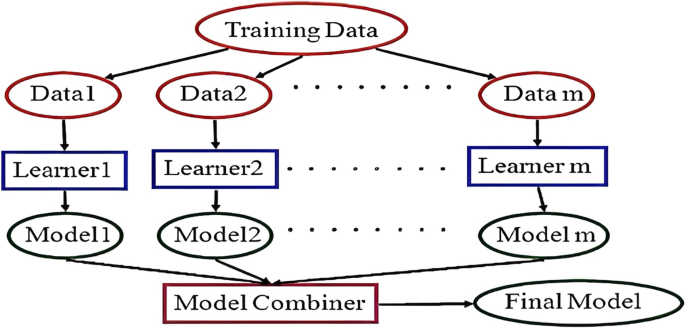
由于网络欺凌对受害者个人和整个社会都有影响,因此近年来对辱骂性语言及其检测的研究引起了人们的关注。由于 Facebook、Instagram、Twitter 等社交媒体网站的访问范围如此广泛,仇恨言论、欺凌、性别歧视、种族主义、攻击性内容、骚扰、恶意评论和其他类型的虐待行为都大幅增加。由于检测、监管和限制社交网站上有害内容传播的关键要求,我们进行了这项研究,以自动检测攻击性语言或网络欺凌。我们创建了一个新的阿拉伯平衡数据集,用于攻击性检测过程,因为模型的平衡数据集将提高模型的准确性。最近,使用集成机器学习提高了单个分类器的性能。本研究的目的是检查几种单一和集成机器学习算法在识别包含粗言秽语和网络欺凌的阿拉伯文本方面的有效性。将它们应用于三个阿拉伯数据集,我们为此选择了三个机器学习分类器和三个集成模型。其中两个是公众可以轻松访问的令人反感的数据集,而第三个是创建的。结果表明,单一学习器机器学习策略不如集成机器学习方法。投票执行是性能最佳的经过训练的集成机器学习分类器,对于相同的数据集,其性能优于最佳的单个学习器分类器(65.1%、76.2% 和 98%),准确度得分为(71.0)。1%、76.7% 和 98.5%)对于使用的三个数据集中的每一个。最后,我们通过对阿拉伯网络欺凌数据集的超参数调整来提高投票技术的性能。
"点击查看英文标题和摘要"
































 京公网安备 11010802027423号
京公网安备 11010802027423号