当前位置:
X-MOL 学术
›
Peer-to-Peer Netw. Appl.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
ASTPPO:一种基于注意力机制和时空相关性的近端策略优化算法,用于软件定义网络中的路由优化
Peer-to-Peer Networking and Applications ( IF 3.3 ) Pub Date : 2023-06-30 , DOI: 10.1007/s12083-023-01489-7
Junyan Chen , Xuefeng Huang , Yong Wang , Hongmei Zhang , Cenhuishan Liao , Xiaolan Xie , Xinmei Li , Wei Xiao

"点击查看英文标题和摘要"
更新日期:2023-06-30
Peer-to-Peer Networking and Applications ( IF 3.3 ) Pub Date : 2023-06-30 , DOI: 10.1007/s12083-023-01489-7
Junyan Chen , Xuefeng Huang , Yong Wang , Hongmei Zhang , Cenhuishan Liao , Xiaolan Xie , Xinmei Li , Wei Xiao
|
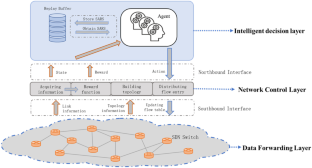
目前,现有的在软件定义网络(SDN)上部署深度强化学习实现路由优化的研究并未考虑网络全局的时空相关性,性能尚未达到极致。鉴于上述问题,本研究提出一种基于注意力机制和时空相关性(ASTPPO)的近端策略优化算法来优化SDN路由问题。首先,我们使用门控循环单元(GRU)和图注意网络(GAT)提取状态信息中的时空相关特征,为强化学习决策提供包含更多环境的隐式信息。其次,我们使用skip-connect方法将隐式和直接相关的信息连接到多层感知器中,提高模型的学习效率和感知能力。最后,我们通过静态和动态流量实验证明了 ASTPPO 的有效性。受益于全局视角的时空相关性学习,ASTPPO 在不同的流量强度要求和网络拓扑下比其他强化学习基线算法表现出更好的负载均衡和拥塞控制。仿真结果表明,ASTPPO算法在静态和动态流量场景下较次优算法分别提高了9.02%和15.07%。ASTPPO 在不同的流量强度要求和网络拓扑下比其他强化学习基线算法表现出更好的负载平衡和拥塞控制。仿真结果表明,ASTPPO算法在静态和动态流量场景下较次优算法分别提高了9.02%和15.07%。ASTPPO 在不同的流量强度要求和网络拓扑下比其他强化学习基线算法表现出更好的负载平衡和拥塞控制。仿真结果表明,ASTPPO算法在静态和动态流量场景下较次优算法分别提高了9.02%和15.07%。
"点击查看英文标题和摘要"
































 京公网安备 11010802027423号
京公网安备 11010802027423号