当前位置:
X-MOL 学术
›
Mobile Netw. Appl.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
用于文本隐私保护的差分私有递归变分自动编码器
Mobile Networks and Applications ( IF 2.3 ) Pub Date : 2023-06-14 , DOI: 10.1007/s11036-023-02096-9 Yuyang Wang , Xianjia Meng , Ximeng Liu

"点击查看英文标题和摘要"
更新日期:2023-06-14
Mobile Networks and Applications ( IF 2.3 ) Pub Date : 2023-06-14 , DOI: 10.1007/s11036-023-02096-9 Yuyang Wang , Xianjia Meng , Ximeng Liu
|
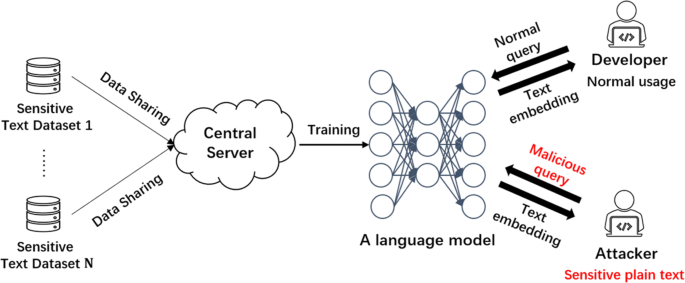
深度学习技术已广泛应用于自然语言处理(NLP)任务,并取得了显着进步。然而,深度学习模型的训练依赖于大量数据,其中可能涉及电子病历等敏感信息。攻击者可以从模型中推断出敏感信息,从而导致隐私泄露。为了解决这个问题,我们提出了一种差分隐私循环变分自动编码器(DP-RVAE),它可以生成模拟数据来代替敏感数据集以保护隐私。为了生成高实用性的合成文本,将一部分敏感文本数据用作模型的条件输入,并使用 dropout 和噪声扰动机制来保护差分隐私。此外,我们将提议的 DP-RVAE 扩展到联邦学习环境,并为 NLP 任务设计了一种新颖的训练范式。具体来说,DP-RVAE被部署到客户端来训练和生成个性化文本。这些 DP-RVAE 模型将通过联合优化 (FedOPT) 算法进行聚合和更新,从而可以很好地保存个人信息。我们通过对推文抑郁情绪和 IMDB 评论数据集的文本分类任务来评估我们提出的 DP-RVAE。与典型的集中训练和联邦学习方法相比,我们的 DP-RVAE 的平均测试准确率分别提高了 5.90% 和 3.94%。我们还对从现实世界收集的医学描述数据集进行了关键词推理攻击实验。与典型的差分隐私保护方法相比,DP-RVAE 的平均攻击准确率下降了 15.2%。实验结果表明,DP-RVAE 可以应用于 NLP 模型,以在保护敏感隐私的同时提高准确性。
"点击查看英文标题和摘要"

















































 京公网安备 11010802027423号
京公网安备 11010802027423号