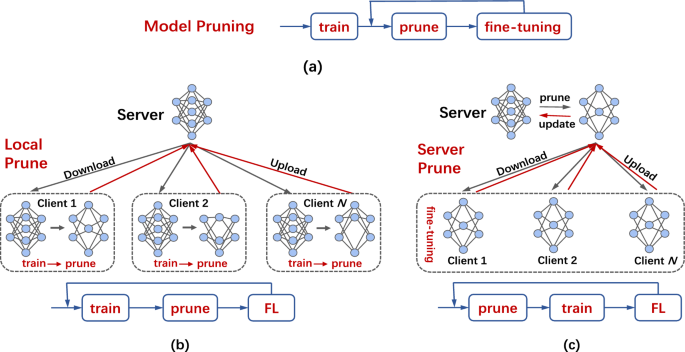
联邦学习是边缘训练的有效解决方案,但边缘设备的带宽有限和计算资源不足限制了其部署。与现有的量化和稀疏化等只考虑通信效率的方法不同,本文提出了一种基于模型剪枝的高效联邦训练框架,以同时解决计算和通信资源不足的问题。首先,框架在全局模型发布前动态选择神经元或卷积核,剪枝出一个当前最优的子网,然后将压缩后的模型下发给各个客户端进行训练。然后,我们开发了一个新的参数聚合更新方案,为全局模型参数提供训练机会,通过模型重构和参数重用保持完整的模型结构,减少剪枝带来的误差。最后,大量实验表明,我们提出的框架在 IID 和非 IID 数据集上均实现了卓越的性能,从而减少了上游和下游通信,同时保持了全局模型的准确性并降低了客户端计算成本。例如,在精度超过基线的情况下,MNIST/FC 的计算量减少了 72.27%,内存使用量减少了 72.17%;对于 CIFAR10/VGG16,计算量减少了 63.39%,内存使用量减少了 59.78%。大量实验表明,我们提出的框架在 IID 和非 IID 数据集上均实现了卓越的性能,从而减少了上游和下游通信,同时保持了全局模型的准确性并降低了客户端计算成本。例如,在精度超过基线的情况下,MNIST/FC 的计算量减少了 72.27%,内存使用量减少了 72.17%;对于 CIFAR10/VGG16,计算量减少了 63.39%,内存使用量减少了 59.78%。大量实验表明,我们提出的框架在 IID 和非 IID 数据集上均实现了卓越的性能,从而减少了上游和下游通信,同时保持了全局模型的准确性并降低了客户端计算成本。例如,在精度超过基线的情况下,MNIST/FC 的计算量减少了 72.27%,内存使用量减少了 72.17%;对于 CIFAR10/VGG16,计算量减少了 63.39%,内存使用量减少了 59.78%。
 "点击查看英文标题和摘要"
"点击查看英文标题和摘要"
Efficient federated learning on resource-constrained edge devices based on model pruning
Federated learning is an effective solution for edge training, but the limited bandwidth and insufficient computing resources of edge devices restrict its deployment. Different from existing methods that only consider communication efficiency such as quantization and sparsification, this paper proposes an efficient federated training framework based on model pruning to simultaneously address the problem of insufficient computing and communication resources. First, the framework dynamically selects neurons or convolution kernels before the global model release, pruning a current optimal subnet and then issues the compressed model to each client for training. Then, we develop a new parameter aggregation update scheme, which provides training opportunities for global model parameters and maintains the complete model structure through model reconstruction and parameter reuse, reducing the error caused by pruning. Finally, extensive experiments show that our proposed framework achieves superior performance on both IID and non-IID datasets, which reduces upstream and downstream communication while maintaining the accuracy of the global model and reducing client computing costs. For example, with accuracy exceeding the baseline, computation is reduced by 72.27% and memory usage is reduced by 72.17% for MNIST/FC; and computation is reduced by 63.39% and memory usage is reduced by 59.78% for CIFAR10/VGG16.



















































 京公网安备 11010802027423号
京公网安备 11010802027423号