当前位置:
X-MOL 学术
›
Laser Photonics Rev.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Easily Scalable Photonic Tensor Core Based on Tunable Units with Single Internal Phase Shifters
Laser & Photonics Reviews ( IF 9.8 ) Pub Date : 2023-04-24 , DOI: 10.1002/lpor.202300001 Ying Huang 1 , Hengsong Yue 1 , Wei Ma 1 , Yiyuan Zhang 1 , Yao Xiao 2 , Weiping Wang 3 , Yong Tang 4 , Xiaoyan Hu 3 , He Tang 2 , Tao Chu 1
Laser & Photonics Reviews ( IF 9.8 ) Pub Date : 2023-04-24 , DOI: 10.1002/lpor.202300001 Ying Huang 1 , Hengsong Yue 1 , Wei Ma 1 , Yiyuan Zhang 1 , Yao Xiao 2 , Weiping Wang 3 , Yong Tang 4 , Xiaoyan Hu 3 , He Tang 2 , Tao Chu 1
Affiliation
|
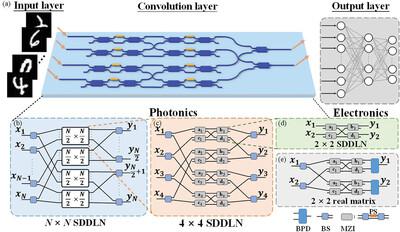
Photonic neural networks (PNNs) show tremendous potential for artificial intelligence applications due to their higher computational rates than their traditional electronic counterpart. However, the scale-up of PNN relies on the number of cascaded computing units, which is limited by the accumulated transmission attenuation. Here, a topology of PNN with Mach–Zehnder interferometers based on a single-tuned phase shifter that implements arbitrary nonnegative or real-valued matrices for vector-matrix multiplication is proposed. Compared with the universal matrix mesh, the new configuration exhibits two orders of magnitude lower optical path loss and a twofold reduction in the number of the tunable phase shifter. An 8 × 8 reconfigurable chip is designed and fabricated, and it is experimentally verified that the 2 × 4 nonnegative-valued matrix and the 2 × 2 real-valued matrix are implemented in the proposed topology. Higher than 85% inference accuracies are obtained in the Modified National Institute of Standards and Technology handwritten digit recognition tasks with these matrices in the PNNs. Therefore, with much lower optical path loss and comparable computing accuracy, the proposed PNN configuration can be easily scaled up to tackle higher dimensional matrix multiplication, which is highly desired in tasks like voice and image recognition.
中文翻译:

基于具有单个内部移相器的可调谐单元的可轻松扩展的光子张量核心
光子神经网络(PNN)由于其比传统电子网络更高的计算速率,在人工智能应用方面显示出巨大的潜力。然而,PNN 的扩展依赖于级联计算单元的数量,而级联计算单元的数量受到累积传输衰减的限制。这里,提出了一种基于单调谐移相器的带有马赫-曾德干涉仪的 PNN 拓扑,该移相器实现了任意非负或实值矩阵的矢量矩阵乘法。与通用矩阵网格相比,新配置的光路损耗降低了两个数量级,并且可调谐移相器的数量减少了一倍。设计并制造了8×8可重构芯片,并通过实验验证了该拓扑中2×4非负值矩阵和2×2实值矩阵的实现。使用 PNN 中的这些矩阵,在修改后的国家标准与技术研究所手写数字识别任务中获得了高于 85% 的推理精度。因此,凭借更低的光路损耗和相当的计算精度,所提出的 PNN 配置可以轻松扩展以处理更高维的矩阵乘法,这在语音和图像识别等任务中是非常需要的。
更新日期:2023-04-24
中文翻译:
基于具有单个内部移相器的可调谐单元的可轻松扩展的光子张量核心
光子神经网络(PNN)由于其比传统电子网络更高的计算速率,在人工智能应用方面显示出巨大的潜力。然而,PNN 的扩展依赖于级联计算单元的数量,而级联计算单元的数量受到累积传输衰减的限制。这里,提出了一种基于单调谐移相器的带有马赫-曾德干涉仪的 PNN 拓扑,该移相器实现了任意非负或实值矩阵的矢量矩阵乘法。与通用矩阵网格相比,新配置的光路损耗降低了两个数量级,并且可调谐移相器的数量减少了一倍。设计并制造了8×8可重构芯片,并通过实验验证了该拓扑中2×4非负值矩阵和2×2实值矩阵的实现。使用 PNN 中的这些矩阵,在修改后的国家标准与技术研究所手写数字识别任务中获得了高于 85% 的推理精度。因此,凭借更低的光路损耗和相当的计算精度,所提出的 PNN 配置可以轻松扩展以处理更高维的矩阵乘法,这在语音和图像识别等任务中是非常需要的。
































 京公网安备 11010802027423号
京公网安备 11010802027423号