The Journal of Supercomputing ( IF 2.5 ) Pub Date : 2023-04-16 , DOI: 10.1007/s11227-023-05226-y Marjan Firouznia , Pietro Ruiu , Giuseppe A. Trunfio
|
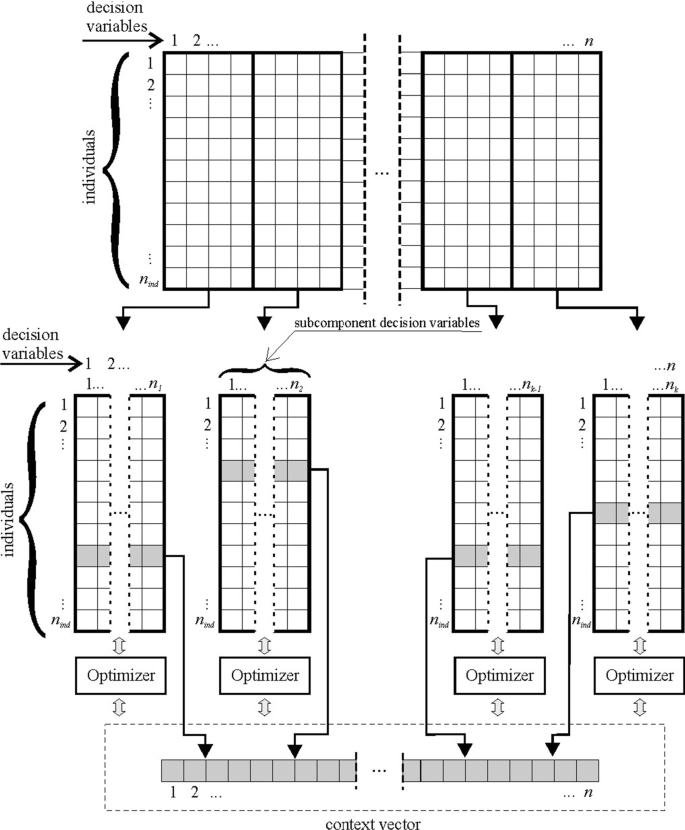
In many fields, it is a common practice to collect large amounts of data characterized by a high number of features. These datasets are at the core of modern applications of supervised machine learning, where the goal is to create an automatic classifier for newly presented data. However, it is well known that the presence of irrelevant features in a dataset can make the learning phase harder and, most importantly, can lead to suboptimal classifiers. Consequently, it is becoming increasingly important to be able to select the right subset of features. Traditionally, optimization metaheuristics have been used with success in the task of feature selection. However, many of the approaches presented in the literature are not applicable to datasets with thousands of features because of the poor scalability of optimization algorithms. In this article, we address the problem using a cooperative coevolutionary approach based on differential evolution. In the proposed algorithm, parallelized for execution on shared-memory architectures, a suitable strategy for reducing the dimensionality of the search space and adjusting the population size during the optimization results in significant performance improvements. A numerical investigation on some high-dimensional and medium-dimensional datasets shows that, in most cases, the proposed approach can achieve higher classification performance than other state-of-the-art methods.
中文翻译:
高维数据集中并行特征选择的自适应协同协同进化差分进化
在许多领域,收集大量具有大量特征的数据是一种常见的做法。这些数据集是监督机器学习现代应用的核心,其目标是为新呈现的数据创建自动分类器。然而,众所周知,数据集中存在不相关的特征会使学习阶段更加困难,最重要的是,会导致分类器次优。因此,能够选择正确的特征子集变得越来越重要。传统上,优化元启发式已成功用于特征选择任务。然而,由于优化算法的可扩展性差,文献中提出的许多方法不适用于具有数千个特征的数据集。在本文中,我们使用基于差异进化的合作共同进化方法来解决这个问题。在所提出的算法中,在共享内存架构上并行执行,在优化过程中采用合适的策略来降低搜索空间的维数和调整种群大小,从而显着提高性能。对一些高维和中维数据集的数值研究表明,在大多数情况下,所提出的方法可以实现比其他最先进的方法更高的分类性能。在优化过程中降低搜索空间维数和调整种群大小的合适策略会显着提高性能。对一些高维和中维数据集的数值研究表明,在大多数情况下,所提出的方法可以实现比其他最先进的方法更高的分类性能。在优化过程中降低搜索空间维数和调整种群大小的合适策略会显着提高性能。对一些高维和中维数据集的数值研究表明,在大多数情况下,所提出的方法可以实现比其他最先进的方法更高的分类性能。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号