Surveys in Geophysics ( IF 4.9 ) Pub Date : 2023-04-10 , DOI: 10.1007/s10712-023-09783-y Ngo Nghi Truyen Huynh , Roland Martin , Thomas Oberlin , Bastien Plazolles
|
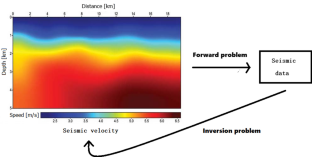
The understanding of subsurface information on the Earth is crucial in numerous fields such as economics of oil and gas, geophysical exploration, archaeology and hydro-geophysics, particularly in a context of climate change. The methodology consists in reconstructing the seismic velocity model of the near surface, that contains information about the basement structure, by solving the inverse problem and resolving the related complex nonlinear systems with the data collected from seismic experiments and measurements. In the last few years, many deep neural networks have been proposed to simplify the seismic inversion problem based, for instance, on automatic differentiation of the adjoint operator, or on automatic arrival time picking. However, such approaches require a large amount of labeled training data, which are hardly available in real applications. We present here a deep learning approach for arrival time picking, aimed to deal with unlabeled data. The main building blocks are transfer learning, as well as a semi-supervised learning strategy where the pseudo-labels are greedily computed with robust regression, and classification algorithms. The hybrid method showcases very high scores when evaluating on synthetic data, and its application to a real dataset containing a limited amount of labeled data shows the computational efficiency and very accurate results.
中文翻译:
具有迁移和半监督学习的近地表地震到达时间选择
对地球地下信息的理解在石油和天然气经济学、地球物理勘探、考古学和水文地球物理学等众多领域至关重要,特别是在气候变化的背景下。该方法包括重建近地表的地震速度模型,其中包含有关基底结构的信息,通过求解逆问题并使用从地震实验和测量中收集的数据解析相关的复杂非线性系统。在过去的几年中,已经提出了许多深度神经网络来简化基于例如伴随算子的自动微分或自动到达时间选择的地震反演问题。然而,这种方法需要大量标记的训练数据,在实际应用中很难获得。我们在这里提出了一种用于选择到达时间的深度学习方法,旨在处理未标记的数据。主要构建块是迁移学习,以及半监督学习策略,其中伪标签是通过鲁棒回归和分类算法贪婪地计算的。混合方法在评估合成数据时表现出非常高的分数,并且将其应用于包含有限数量标记数据的真实数据集显示了计算效率和非常准确的结果。和分类算法。混合方法在评估合成数据时表现出非常高的分数,并且将其应用于包含有限数量标记数据的真实数据集显示了计算效率和非常准确的结果。和分类算法。混合方法在评估合成数据时表现出非常高的分数,并且将其应用于包含有限数量标记数据的真实数据集显示了计算效率和非常准确的结果。
















































 京公网安备 11010802027423号
京公网安备 11010802027423号