当前位置:
X-MOL 学术
›
J. Am. Chem. Soc.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
A Machine Learning Approach to Model Interaction Effects: Development and Application to Alcohol Deoxyfluorination
Journal of the American Chemical Society ( IF 14.4 ) Pub Date : 2023-03-29 , DOI: 10.1021/jacs.2c13093
Andrzej M Żurański 1 , Shivaani S Gandhi 1, 2 , Abigail G Doyle 1, 2
Journal of the American Chemical Society ( IF 14.4 ) Pub Date : 2023-03-29 , DOI: 10.1021/jacs.2c13093
Andrzej M Żurański 1 , Shivaani S Gandhi 1, 2 , Abigail G Doyle 1, 2
Affiliation
|
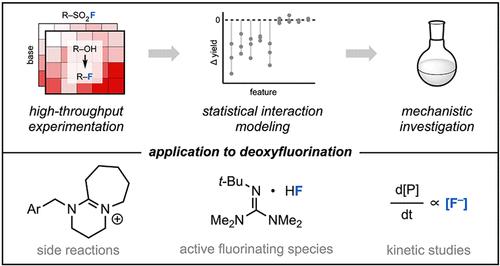
The application of machine learning (ML) techniques to model high-throughput experimentation (HTE) datasets has seen a recent rise in popularity. Nevertheless, the ability to model the interplay between reaction components, known as interaction effects, with ML remains an outstanding challenge. Using a simulated HTE dataset, we find that the presence of irrelevant features poses a strong obstacle to learning interaction effects with common ML algorithms. To address this problem, we propose a two-part statistical modeling approach for HTE datasets: classical analysis of variance of the experiment to identify systematic effects that impact reaction yield across the experiment followed by regression of individual effects using chemistry-informed features. To illustrate this methodology, we use our previously published alcohol deoxyfluorination dataset comprising 740 reactions to build a compact, interpretable generalized additive model that accounts for each significant effect observed in the dataset. We achieve a sizeable performance boost compared to our previously published random forest model, reducing mean absolute error from 18 to 13% and root-mean-squared error from 22 to 17% on a newly generated validation set. Finally, we demonstrate that this approach can facilitate the generation of new mechanistic hypotheses, which, when probed experimentally, can lead to a deeper understanding of chemical reactivity.
中文翻译:

模型交互效应的机器学习方法:酒精脱氧氟化的开发和应用
机器学习 (ML) 技术在模拟高通量实验 (HTE) 数据集方面的应用最近越来越受欢迎。然而,使用 ML 模拟反应组分之间的相互作用(称为相互作用效应)的能力仍然是一个突出的挑战。使用模拟的 HTE 数据集,我们发现不相关特征的存在对使用普通 ML 算法学习交互效果构成了很大的障碍。为了解决这个问题,我们为 HTE 数据集提出了一种由两部分组成的统计建模方法:对实验进行经典方差分析,以确定影响整个实验反应产率的系统效应,然后使用化学信息特征对个体效应进行回归。为了说明这种方法,我们使用我们之前发布的包含 740 个反应的酒精脱氧氟化数据集来构建一个紧凑的、可解释的广义加性模型,该模型解释了数据集中观察到的每个显着影响。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。
更新日期:2023-03-29
中文翻译:
模型交互效应的机器学习方法:酒精脱氧氟化的开发和应用
机器学习 (ML) 技术在模拟高通量实验 (HTE) 数据集方面的应用最近越来越受欢迎。然而,使用 ML 模拟反应组分之间的相互作用(称为相互作用效应)的能力仍然是一个突出的挑战。使用模拟的 HTE 数据集,我们发现不相关特征的存在对使用普通 ML 算法学习交互效果构成了很大的障碍。为了解决这个问题,我们为 HTE 数据集提出了一种由两部分组成的统计建模方法:对实验进行经典方差分析,以确定影响整个实验反应产率的系统效应,然后使用化学信息特征对个体效应进行回归。为了说明这种方法,我们使用我们之前发布的包含 740 个反应的酒精脱氧氟化数据集来构建一个紧凑的、可解释的广义加性模型,该模型解释了数据集中观察到的每个显着影响。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。与我们之前发布的随机森林模型相比,我们实现了相当大的性能提升,在新生成的验证集上,平均绝对误差从 18% 降低到 13%,均方根误差从 22% 降低到 17%。最后,我们证明这种方法可以促进新的机械假设的产生,当通过实验探索时,可以加深对化学反应性的理解。
































 京公网安备 11010802027423号
京公网安备 11010802027423号