当前位置:
X-MOL 学术
›
Appl. Intell.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
用于文本分类的文本增强对比学习
Applied Intelligence ( IF 3.4 ) Pub Date : 2023-03-09 , DOI: 10.1007/s10489-023-04453-3 Ouyang Jia , Huimin Huang , Jiaxin Ren , Luodi Xie , Yinyin Xiao

"点击查看英文标题和摘要"
更新日期:2023-03-11
Applied Intelligence ( IF 3.4 ) Pub Date : 2023-03-09 , DOI: 10.1007/s10489-023-04453-3 Ouyang Jia , Huimin Huang , Jiaxin Ren , Luodi Xie , Yinyin Xiao
|
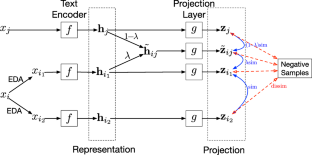
各种对比学习模型已成功应用于下游任务的表示学习。对比学习中使用的正样本通常来自增强数据,这提高了许多计算机视觉任务的性能,但仍未充分用于自然语言处理任务,如文本分类。现有的数据增强方法很少应用于NLP领域的对比学习。在本文中,我们提出了一种文本增强对比学习表示模型,TACLR,将简单的文本增强技术(即同义词替换、随机插入、随机交换和随机删除)和 textMixup 增强方法与文本分类任务的对比学习相结合。此外,我们提出了一种统一的方法,可以灵活地适应监督、半监督和无监督学习。五个文本分类数据集的实验结果表明,我们的 TACLR 可以显着提高文本分类的准确性。我们还提供广泛的消融研究,以探索我们模型每个组件的有效性。我们工作的源代码可从 https://gitlab.com/models-for-paper/taclr 公开获得。
"点击查看英文标题和摘要"






































 京公网安备 11010802027423号
京公网安备 11010802027423号