当前位置:
X-MOL 学术
›
Anal. Chem.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Bulk Affinity Assays in Aptamer Selection: Challenges, Theory, and Workflow
Analytical Chemistry ( IF 6.7 ) Pub Date : 2022-10-27 , DOI: 10.1021/acs.analchem.2c03173 Eden Teclemichael 1 , An T H Le 1 , Svetlana M Krylova 1 , Tong Ye Wang 1 , Sergey N Krylov 1
Analytical Chemistry ( IF 6.7 ) Pub Date : 2022-10-27 , DOI: 10.1021/acs.analchem.2c03173 Eden Teclemichael 1 , An T H Le 1 , Svetlana M Krylova 1 , Tong Ye Wang 1 , Sergey N Krylov 1
Affiliation
|
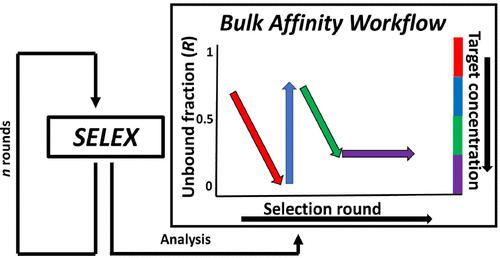
Selection of oligonucleotide aptamers involves consecutive rounds of affinity isolation of target-binding oligonucleotides from a random-sequence oligonucleotide library. Every next round produces an aptamer-enriched library with progressively higher fitness for tight binding to the target. The progress of enrichment can only be accurately assessed with bulk affinity assays in which a library is mixed with the target and one of two quantitative parameters, the fraction of the unbound library (R) or the equilibrium dissociation constant (Kd), is determined. These quantitative parameters are used to help researchers make a key decision of either continuing or stopping the selection. Despite the importance of this decision, the suitability of R and Kd for bulk affinity assays has never been studied theoretically, and researchers rely on intuition when choosing between them. Different approaches used for bulk affinity assays expectedly hinder comparative analyses of selections. Our current work has two goals: to give bulk affinity assays a thorough theoretical consideration and to propose a scientifically justified and practical bulk-affinity-assay approach. We postulate a formal criterion of suitability: a quantitative parameter must satisfy the principle of superposition. R satisfies this principle, while Kd does not, suggesting R as a theoretically preferable parameter. Further, we propose a solution for two limitations of R: its dependence on target concentration and narrow dynamic range. Finally, we demonstrate the use of this algorithm in both computer-simulated and experimental aptamer selection. This study sets a cornerstone in the theory of bulk affinity assays, and it provides researchers with a scientifically sound and instructive approach for conducting bulk affinity assays.
中文翻译:

适体选择中的批量亲和力分析:挑战、理论和工作流程
寡核苷酸适体的选择涉及从随机序列寡核苷酸文库中连续轮次亲和分离靶标结合寡核苷酸。每一轮都会产生一个富含适体的文库,其适应性逐渐提高,可以紧密结合到目标上。富集的进展只能通过批量亲和分析来准确评估,在这种分析中,文库与靶标混合,并且确定两个定量参数之一,即未结合文库的分数 ( R ) 或平衡解离常数 ( Kd ) . 这些定量参数用于帮助研究人员做出继续或停止选择的关键决定。尽管这个决定很重要,但R和大量亲和分析的Kd从未在理论上进行过研究,研究人员在选择它们时依靠直觉。用于大量亲和力测定的不同方法预计会阻碍选择的比较分析。我们目前的工作有两个目标:对批量亲和分析进行全面的理论考虑,并提出一种科学合理且实用的批量亲和分析方法。我们假设了一个正式的适用性标准:一个定量参数必须满足叠加原则。R满足这个原则,而K d不满足,这表明R是理论上更可取的参数。此外,我们针对R的两个限制提出了一个解决方案:它依赖于目标浓度和窄动态范围。最后,我们展示了该算法在计算机模拟和实验适体选择中的应用。这项研究为批量亲和分析的理论奠定了基石,它为研究人员提供了一种科学合理且具有指导意义的方法来进行批量亲和分析。
更新日期:2022-10-27
中文翻译:
适体选择中的批量亲和力分析:挑战、理论和工作流程
寡核苷酸适体的选择涉及从随机序列寡核苷酸文库中连续轮次亲和分离靶标结合寡核苷酸。每一轮都会产生一个富含适体的文库,其适应性逐渐提高,可以紧密结合到目标上。富集的进展只能通过批量亲和分析来准确评估,在这种分析中,文库与靶标混合,并且确定两个定量参数之一,即未结合文库的分数 ( R ) 或平衡解离常数 ( Kd ) . 这些定量参数用于帮助研究人员做出继续或停止选择的关键决定。尽管这个决定很重要,但R和大量亲和分析的Kd从未在理论上进行过研究,研究人员在选择它们时依靠直觉。用于大量亲和力测定的不同方法预计会阻碍选择的比较分析。我们目前的工作有两个目标:对批量亲和分析进行全面的理论考虑,并提出一种科学合理且实用的批量亲和分析方法。我们假设了一个正式的适用性标准:一个定量参数必须满足叠加原则。R满足这个原则,而K d不满足,这表明R是理论上更可取的参数。此外,我们针对R的两个限制提出了一个解决方案:它依赖于目标浓度和窄动态范围。最后,我们展示了该算法在计算机模拟和实验适体选择中的应用。这项研究为批量亲和分析的理论奠定了基石,它为研究人员提供了一种科学合理且具有指导意义的方法来进行批量亲和分析。
































 京公网安备 11010802027423号
京公网安备 11010802027423号