CCF Transactions on High Performance Computing Pub Date : 2022-10-26 , DOI: 10.1007/s42514-022-00128-6
Qiao Sun , Wenjing Ma , Jiachang Sun , Huiyuan Li
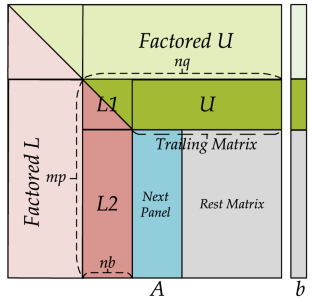
|
HPL (High Performance Linpack) is a widely accepted benchmark for evaluating high-performance computer clusters. It produces performance results by solving large linear systems, which serves as the measurement of the Top-500 supercomputer ranking. With the increasingly wider performance gap between CPU and GPGPU, non-computing-intensive workload becomes more time-critical and impedes the sustained HPL performance more severely. Traditionally on multi-GPGPU platform, a one-to-one mapping between processes and devices is enforced in HPL. While it brings simplicity for implementation, the even share of the system resources among the processes in each node leads to lower system utilization in the major time-critical algorithmic steps of HPL. In this paper, we propose a novel device-centric HPL approach for current main-stream multi-GPGPU platforms, where each process can make full use of the resources of a node, including accelerators, CPU sockets, PCI-e buses and memory/network bandwidth etc. As a result, the workload on the CPU-end and the inter-process communication are greatly boosted due to higher system utilization, while the computation on the device-end remains efficient. Experiment shows that in the case of a single workstation with 4 GPGPUs, our approach can achieve more than \(80\%\) of the theoretical peak and nearly \(95\%\) of the dgemm performance, which is significantly higher than the state-of-the-art counterpart on the same platform. In the case of multi-GPGPU clusters, we also largely improve the sustained performance and efficiency as compared to previous works of HPL incorporating multi-GPGPU features. Further, based on both performance analysis and the experimental results, we believe that our approach may serve as a competitive cornerstone for further optimizations on future heterogeneous platforms.
中文翻译:
向多 GPGPU 集群发展 HPL 基准
HPL(High Performance Linpack)是一种被广泛接受的用于评估高性能计算机集群的基准。它通过求解大型线性系统产生性能结果,作为 Top-500 超级计算机排名的衡量标准。随着 CPU 和 GPGPU 之间的性能差距越来越大,非计算密集型工作负载变得更加时间关键,并且更加严重地阻碍了持续的 HPL 性能。传统上,在多 GPGPU 平台上,HPL 中强制执行进程和设备之间的一对一映射。虽然它为实现带来了简单性,但每个节点中进程之间系统资源的均匀共享导致 HPL 的主要时间关键算法步骤中的系统利用率较低。在本文中,我们提出了一种新的以设备为中心的 HPL 方法,用于当前主流的多 GPGPU 平台,每个进程都可以充分利用一个节点的资源,包括加速器、CPU 插槽、PCI-e 总线和内存/网络带宽等。因此,CPU 端的工作量和进程间通信的工作量都很大。由于更高的系统利用率而得到提升,而设备端的计算仍然有效。实验表明,在具有 4 个 GPGPU 的单个工作站的情况下,我们的方法可以实现超过\(80\%\)的理论峰值和接近\(95\%\)的dgemm性能,显着高于同一平台上最先进的对应物。在多 GPGPU 集群的情况下,与之前结合多 GPGPU 特征的 HPL 工作相比,我们还大大提高了持续性能和效率。此外,基于性能分析和实验结果,我们相信我们的方法可以作为未来异构平台进一步优化的竞争基石。
































 京公网安备 11010802027423号
京公网安备 11010802027423号