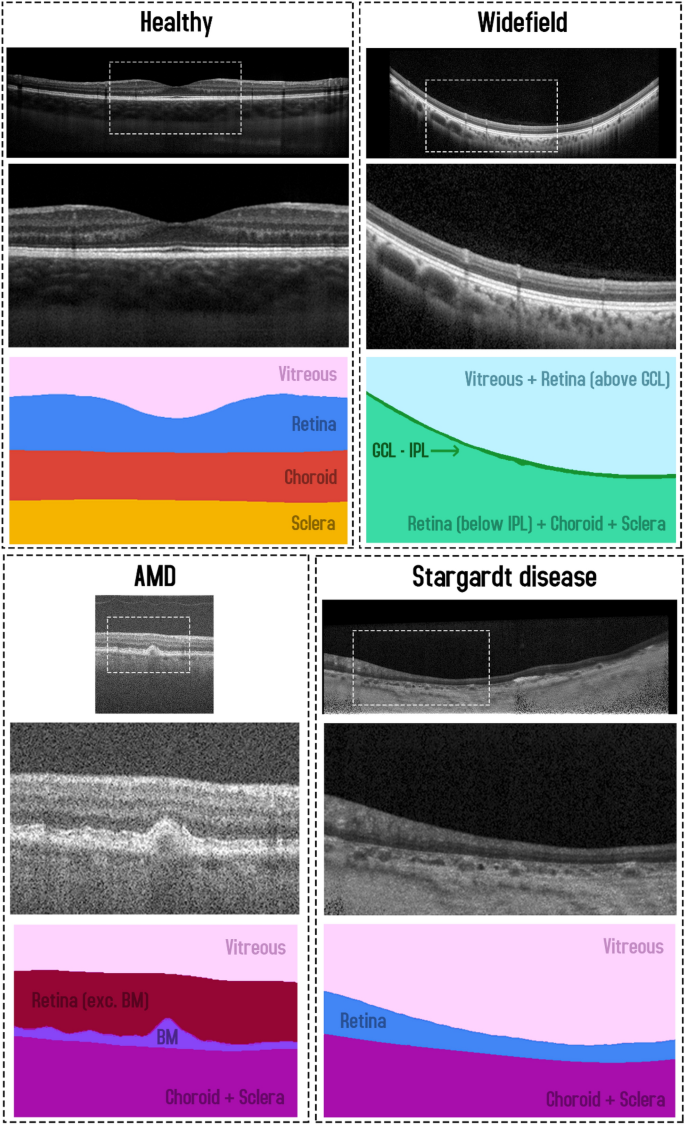
深度学习方法为后段 OCT 图像中的视网膜层分割提供了一种快速、准确和自动化的方法。由于采用 U-Net 的语义分割方法的成功,已经开发了广泛的变体和改进方法并将其应用于 OCT 分割。不幸的是,由于缺乏全面的比较研究,以及在之前的比较中网络之间缺乏适当的匹配,以及在研究之间使用不同的 OCT 数据集,这些方法的相对性能很难确定用于 OCT 视网膜层分割。在本文中,对来自一系列不同人群、眼部病变、采集参数、仪器和分割任务。评估的 U-Net 架构变体包括一些以前没有针对 OCT 分割进行过探索的变体。使用 Dice 系数来评估分割性能,在四个数据集中的大多数测试架构之间发现了最小的差异。每个池化块使用一个额外的卷积层可以对所有四个数据集的所有架构的分割性能进行小幅改进。这一发现强调了仔细的架构比较(例如,确保使用相同数量的层匹配网络)以获得对完全语义模型的真实和无偏见的性能评估的重要性。全面的,这项研究表明,普通 U-Net 足以用于 OCT 视网膜层分割,并且对于这一特定任务而言,最先进的方法和其他架构更改可能是不必要的,特别是考虑到相关的复杂性增加和边缘速度较慢观察到的性能增益。鉴于 U-Net 模型及其变体代表了最常用的图像分割方法之一,这里几个数据集的一致发现可能会转化为许多其他 OCT 数据集和研究。这将通过节省实验和模型开发的时间和成本以及通过选择更简单的模型减少实践中的推理时间来提供显着的价值。特别是考虑到观察到的边际性能增益相关的复杂性增加和速度变慢。鉴于 U-Net 模型及其变体代表了最常用的图像分割方法之一,这里几个数据集的一致发现可能会转化为许多其他 OCT 数据集和研究。这将通过节省实验和模型开发的时间和成本以及通过选择更简单的模型减少实践中的推理时间来提供显着的价值。特别是考虑到观察到的边际性能增益相关的复杂性增加和速度变慢。鉴于 U-Net 模型及其变体代表了最常用的图像分割方法之一,这里几个数据集的一致发现可能会转化为许多其他 OCT 数据集和研究。这将通过节省实验和模型开发的时间和成本以及通过选择更简单的模型减少实践中的推理时间来提供显着的价值。
 "点击查看英文标题和摘要"
"点击查看英文标题和摘要"
A comparison of deep learning U-Net architectures for posterior segment OCT retinal layer segmentation
Deep learning methods have enabled a fast, accurate and automated approach for retinal layer segmentation in posterior segment OCT images. Due to the success of semantic segmentation methods adopting the U-Net, a wide range of variants and improvements have been developed and applied to OCT segmentation. Unfortunately, the relative performance of these methods is difficult to ascertain for OCT retinal layer segmentation due to a lack of comprehensive comparative studies, and a lack of proper matching between networks in previous comparisons, as well as the use of different OCT datasets between studies. In this paper, a detailed and unbiased comparison is performed between eight U-Net architecture variants across four different OCT datasets from a range of different populations, ocular pathologies, acquisition parameters, instruments and segmentation tasks. The U-Net architecture variants evaluated include some which have not been previously explored for OCT segmentation. Using the Dice coefficient to evaluate segmentation performance, minimal differences were noted between most of the tested architectures across the four datasets. Using an extra convolutional layer per pooling block gave a small improvement in segmentation performance for all architectures across all four datasets. This finding highlights the importance of careful architecture comparison (e.g. ensuring networks are matched using an equivalent number of layers) to obtain a true and unbiased performance assessment of fully semantic models. Overall, this study demonstrates that the vanilla U-Net is sufficient for OCT retinal layer segmentation and that state-of-the-art methods and other architectural changes are potentially unnecessary for this particular task, especially given the associated increased complexity and slower speed for the marginal performance gains observed. Given the U-Net model and its variants represent one of the most commonly applied image segmentation methods, the consistent findings across several datasets here are likely to translate to many other OCT datasets and studies. This will provide significant value by saving time and cost in experimentation and model development as well as reduced inference time in practice by selecting simpler models.


































 京公网安备 11010802027423号
京公网安备 11010802027423号