Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
通过自动生成的语料库提取材料信息
Scientific Data ( IF 5.8 ) Pub Date : 2022-07-13 , DOI: 10.1038/s41597-022-01492-2
Rongen Yan 1 , Xue Jiang 2, 3 , Weiren Wang 2 , Depeng Dang 1 , Yanjing Su 2

"点击查看英文标题和摘要"
更新日期:2022-07-13
Scientific Data ( IF 5.8 ) Pub Date : 2022-07-13 , DOI: 10.1038/s41597-022-01492-2
Rongen Yan 1 , Xue Jiang 2, 3 , Weiren Wang 2 , Depeng Dang 1 , Yanjing Su 2
Affiliation
|
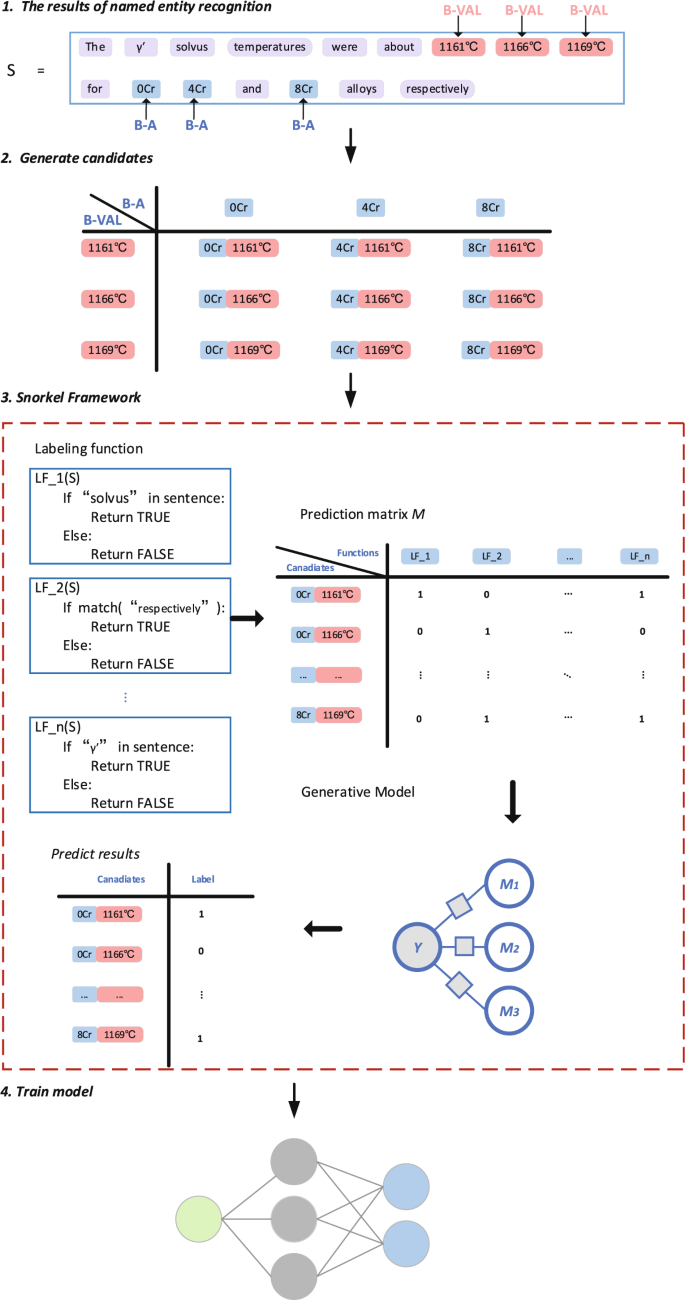
自然语言处理(NLP)中的信息提取(IE)旨在从非结构化文本中提取结构化信息,以帮助计算机理解自然语言。基于机器学习的 IE 方法带来了更多的智能和可能性,但需要广泛而准确的标记语料库。在材料科学领域,提供可靠的标签是一项艰巨的任务,需要许多专业人士的努力。为了在 IE 过程中减少人工干预并自动生成材料语料库,在这项工作中,我们提出了一个通过自动生成语料库的材料半监督 IE 框架。以我们之前工作中的高温合金数据提取为例,所提出的使用 Snorkel 的框架会自动标记包含属性值的语料库。然后采用有序神经元-长短期记忆(ON-LSTM)网络在生成的语料上训练信息提取模型。实验结果表明,F1-scoreγ '高温合金的固溶线温度、密度和固相线温度分别为83.90%、94.02%、89.27%。此外,我们对其他材料进行了类似的实验,实验结果表明所提出的框架在材料领域是通用的。
"点击查看英文标题和摘要"
































 京公网安备 11010802027423号
京公网安备 11010802027423号