Applied Intelligence ( IF 3.4 ) Pub Date : 2022-04-27 , DOI: 10.1007/s10489-022-03440-4 Dibyendu Bikash Seal 1 , Vivek Das 2 , Rajat K. De 3
|
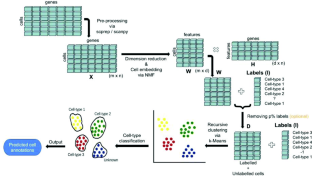
单细胞 RNA 测序 (scRNA-seq) 允许以细胞分辨率进行全局转录组分析,从而识别潜在的细胞类型和相应的谱系。这种细胞类型识别和注释在很大程度上依赖于模型,这些模型通过在具有准确注释标签的大量单个细胞上训练自己来学习。目前,这项细胞类型注释任务是基于对每个具有统计学意义的细胞组的标记基因的检查来完成的。这既具有挑战性又耗时。在本文中,我们提出了一种基于非负矩阵分解 (NMF) 和递归 k-means 算法的半监督单元类型标注方法,称为 CASSL。半监督模型能够在有限数量的标记数据的帮助下学习大量未标记数据的标签。CASSL 的有效性已在八个公开可用的人类和小鼠 scRNA-seq 数据集上得到证明,这些数据集涉及不同的器官和协议。它已经能够以高精度正确注释大多数未标记的细胞。它还因其聚类解决方案的正确性、不同百分比的缺失标签的鲁棒性以及执行时间而进行了评估。与最先进的无监督和半监督细胞类型注释方法相比,CASSL 在大多数数据集的所有指标上始终优于其他方法。与最先进的监督方法相比,它也显示出具有竞争力的结果。CASSL 的有效性已在八个公开可用的人类和小鼠 scRNA-seq 数据集上得到证明,这些数据集涉及不同的器官和协议。它已经能够以高精度正确注释大多数未标记的细胞。它还因其聚类解决方案的正确性、不同百分比的缺失标签的鲁棒性以及执行时间而进行了评估。与最先进的无监督和半监督细胞类型注释方法相比,CASSL 在大多数数据集的所有指标上始终优于其他方法。与最先进的监督方法相比,它也显示出具有竞争力的结果。CASSL 的有效性已在八个公开可用的人类和小鼠 scRNA-seq 数据集上得到证明,这些数据集涉及不同的器官和协议。它已经能够以高精度正确注释大多数未标记的细胞。它还因其聚类解决方案的正确性、不同百分比的缺失标签的鲁棒性以及执行时间而进行了评估。与最先进的无监督和半监督细胞类型注释方法相比,CASSL 在大多数数据集的所有指标上始终优于其他方法。与最先进的监督方法相比,它也显示出具有竞争力的结果。它已经能够以高精度正确注释大多数未标记的细胞。它还因其聚类解决方案的正确性、不同百分比的缺失标签的鲁棒性以及执行时间而进行了评估。与最先进的无监督和半监督细胞类型注释方法相比,CASSL 在大多数数据集的所有指标上始终优于其他方法。与最先进的监督方法相比,它也显示出具有竞争力的结果。它已经能够以高精度正确注释大多数未标记的细胞。它还因其聚类解决方案的正确性、不同百分比的缺失标签的鲁棒性以及执行时间而进行了评估。与最先进的无监督和半监督细胞类型注释方法相比,CASSL 在大多数数据集的所有指标上始终优于其他方法。与最先进的监督方法相比,它也显示出具有竞争力的结果。CASSL 在大多数数据集的所有指标上始终优于其他指标。与最先进的监督方法相比,它也显示出具有竞争力的结果。CASSL 在大多数数据集的所有指标上始终优于其他指标。与最先进的监督方法相比,它也显示出具有竞争力的结果。
"点击查看英文标题和摘要"
































 京公网安备 11010802027423号
京公网安备 11010802027423号