Applied Intelligence ( IF 3.4 ) Pub Date : 2022-04-09 , DOI: 10.1007/s10489-022-03401-x Tianxiao Gao 1 , Wu Wei 1 , Zhongbin Cai 1 , Qiuda Yu 1 , Zhun Fan 2 , Sheng Quan Xie 3 , Xinmei Wang 4
|
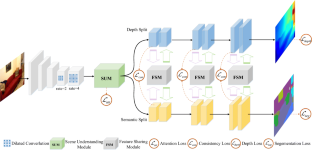
Monocular depth estimation and semantic segmentation are two fundamental goals of scene understanding. Due to the advantages of task interaction, many works have studied the joint-task learning algorithm. However, most existing methods fail to fully leverage the semantic labels, ignoring the provided context structures and only using them to supervise the prediction of segmentation split, which limits the performance of both tasks. In this paper, we propose a network injected with contextual information (CI-Net) to solve this problem. Specifically, we introduce a self-attention block in the encoder to generate an attention map. With supervision from the ideal attention map created by semantic label, the network is embedded with contextual information so that it could understand the scene better and utilize correlated features to make accurate prediction. Besides, a feature-sharing module (FSM) is constructed to make the task-specific features deeply fused, and a consistency loss is devised to ensure that the features mutually guided. We extensively evaluate the proposed CI-Net on NYU-Depth-v2, SUN-RGBD, and Cityscapes datasets. The experimental results validate that our proposed CI-Net could effectively improve the accuracy of semantic segmentation and depth estimation.
中文翻译:
CI-Net:使用上下文信息的联合深度估计和语义分割网络
单目深度估计和语义分割是场景理解的两个基本目标。由于任务交互的优势,很多工作都研究了联合任务学习算法。然而,大多数现有方法未能充分利用语义标签,忽略提供的上下文结构,仅使用它们来监督分割分割的预测,这限制了这两个任务的性能。在本文中,我们提出了一个注入上下文信息的网络(CI-Net)来解决这个问题。具体来说,我们在编码器中引入了一个自注意力块来生成注意力图。在语义标签创建的理想注意力图的监督下,该网络嵌入了上下文信息,以便更好地理解场景并利用相关特征进行准确预测。此外,还构建了一个特征共享模块(FSM)以使特定任务的特征深度融合,并设计了一致性损失以确保特征相互引导。我们在 NYU-Depth-v2、SUN-RGBD 和 Cityscapes 数据集上广泛评估了提议的 CI-Net。实验结果验证了我们提出的 CI-Net 可以有效地提高语义分割和深度估计的准确性。和 Cityscapes 数据集。实验结果验证了我们提出的 CI-Net 可以有效地提高语义分割和深度估计的准确性。和 Cityscapes 数据集。实验结果验证了我们提出的 CI-Net 可以有效地提高语义分割和深度估计的准确性。






























 京公网安备 11010802027423号
京公网安备 11010802027423号