当前位置:
X-MOL 学术
›
Comput. Struct. Biotechnol. J.
›
论文详情
Our official English website, www.x-mol.net, welcomes your
feedback! (Note: you will need to create a separate account there.)
Integration strategies of multi-omics data for machine learning analysis
Computational and Structural Biotechnology Journal ( IF 4.4 ) Pub Date : 2021-06-22 , DOI: 10.1016/j.csbj.2021.06.030 Milan Picard 1 , Marie-Pier Scott-Boyer 1 , Antoine Bodein 1 , Olivier Périn 2 , Arnaud Droit 1
Computational and Structural Biotechnology Journal ( IF 4.4 ) Pub Date : 2021-06-22 , DOI: 10.1016/j.csbj.2021.06.030 Milan Picard 1 , Marie-Pier Scott-Boyer 1 , Antoine Bodein 1 , Olivier Périn 2 , Arnaud Droit 1
Affiliation
|
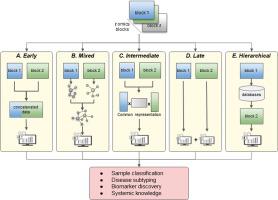
Increased availability of high-throughput technologies has generated an ever-growing number of omics data that seek to portray many different but complementary biological layers including genomics, epigenomics, transcriptomics, proteomics, and metabolomics. New insight from these data have been obtained by machine learning algorithms that have produced diagnostic and classification biomarkers. Most biomarkers obtained to date however only include one omic measurement at a time and thus do not take full advantage of recent multi-omics experiments that now capture the entire complexity of biological systems.
中文翻译:

用于机器学习分析的多组学数据整合策略
高通量技术的可用性不断增加,产生了越来越多的组学数据,这些数据试图描绘许多不同但互补的生物层,包括基因组学、表观基因组学、转录组学、蛋白质组学和代谢组学。机器学习算法从这些数据中获得了新的见解,这些算法产生了诊断和分类生物标志物。然而,迄今为止获得的大多数生物标志物一次仅包含一种组学测量,因此没有充分利用最近的多组学实验,这些实验现在捕获了生物系统的整个复杂性。
更新日期:2021-06-22
中文翻译:
用于机器学习分析的多组学数据整合策略
高通量技术的可用性不断增加,产生了越来越多的组学数据,这些数据试图描绘许多不同但互补的生物层,包括基因组学、表观基因组学、转录组学、蛋白质组学和代谢组学。机器学习算法从这些数据中获得了新的见解,这些算法产生了诊断和分类生物标志物。然而,迄今为止获得的大多数生物标志物一次仅包含一种组学测量,因此没有充分利用最近的多组学实验,这些实验现在捕获了生物系统的整个复杂性。
















































 京公网安备 11010802027423号
京公网安备 11010802027423号