Journal of Hydrology ( IF 5.9 ) Pub Date : 2021-06-06 , DOI: 10.1016/j.jhydrol.2021.126508 Pierre-Yves Jeannin , Guillaume Artigue , Christoph Butscher , Yong Chang , Jean-Baptiste Charlier , Lea Duran , Laurence Gill , Andreas Hartmann , Anne Johannet , Hervé Jourde , Alireza Kavousi , Tanja Liesch , Yan Liu , Martin Lüthi , Arnauld Malard , Naomi Mazzilli , Eulogio Pardo-Igúzquiza , Dominique Thiéry , Thomas Reimann , Philip Schuler , Thomas Wöhling , Andreas Wunsch
|
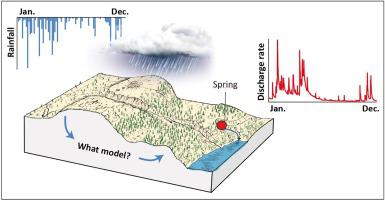
The complexity of karst groundwater flow modelling is reflected by the amount of simulation approaches. The goal of the Karst Modelling Challenge (KMC) is comparing different approaches on one single system using the same data set. Thirteen teams with different computational models for simulating discharge variations at karst springs have applied their respective models on one single data set coming from the Milandre Karst Hydrogeological System (MKHS). The approaches include neural networks, reservoir models, semi-distributed models and fully distributed groundwater models. Four and a half years of hourly or daily meteorological input and hourly discharge data were provided for model calibration. The validation comprised forecasting one year of discharge, without the observed discharge data. The model performance was evaluated using the volume conservation, Nash-Sutcliffe efficiency (NSE) and the Kling-Gupta efficiency (KGE) applied on the total discharge and individual flow components. As a result, the comparison of model performances is a challenging task due to the differences in the model architecture but also required time steps: some of the models require aggregated daily steps while others could be run using hourly data, which provided some interesting differences depending on how the data was transformed. The use of instantaneous data (e.g. value at noon) produces less bias that averaging hourly data over one day. The transformation of hourly into daily data produces a decrease of Nash and KGE of 0.05 to 0.08 (i.e. from 1 to ~0.93). The resulting simulations (forecasted values for year 2016) produced KGEs ranging between 0.83 and 0.37 (0.83 to −0.24 for NSE). Although the simulations matched the monitored flows reasonably well, most models struggled to simulate baseflow conditions accurately. In general, the models that performed the best for this exercise were the global ones (Gardenia and Varkarst), with a limited number of parameters, which can be calibrated using automatic calibration procedures. The neural network models also showed a fair potential, with one providing reasonable results despite the relatively short dataset available for warming-up (4.5 years). Semi-and fully distributed models also suggested that with some more effort they could perform well. The accuracy of model predictions does not seem to increase by using models with more than 9–12 calibration parameters. An evaluation of the relative errors between the forecasted and the observed values revealed that for most models, 50% of the forecasted values contained more than 50% of difference against the observed discharge rate, with 25% having a difference larger than 100%. A significant part of the poorly forecasted values corresponded to base-flow which was surprising given that as base-flow is generally much easier to predict than peak flow. Hence, this shows that modelling approaches and criteria for the calibration are too oriented towards peak-flow sections of the hydrographs, and that improvements could be gained by more focus on the base-flow.
中文翻译:
岩溶建模挑战 1:水文建模结果
岩溶地下水流建模的复杂性体现在模拟方法的数量上。喀斯特建模挑战赛 (KMC) 的目标是在使用相同数据集的单个系统上比较不同的方法。13 个具有不同计算模型的团队模拟岩溶泉水流量变化,已将各自的模型应用于来自 Milandre 岩溶水文地质系统 (MKHS) 的单个数据集。这些方法包括神经网络、水库模型、半分布式模型和完全分布式地下水模型。为模型校准提供了四年半的每小时或每天气象输入和每小时排放数据。验证包括预测一年的排放,没有观察到的排放数据。使用体积守恒、纳什-萨特克利夫效率 (NSE) 和克林-古普塔效率 (KGE) 评估模型性能,应用于总流量和单个流量分量。因此,由于模型架构的差异,模型性能的比较是一项具有挑战性的任务,但也需要时间步长:一些模型需要聚合每日步骤,而其他模型可以使用每小时数据运行,这提供了一些有趣的差异,具体取决于关于数据是如何转换的。使用瞬时数据(例如中午的值)产生的偏差小于一天内平均每小时数据的偏差。将每小时数据转换为每日数据会使 Nash 和 KGE 减少 0.05 至 0.08(即从 1 至 ~0.93)。由此产生的模拟(2016 年的预测值)产生了介于 0 之间的 KGE。83 和 0.37(NSE 为 0.83 到 -0.24)。尽管模拟与监测流量相当匹配,但大多数模型难以准确模拟基流条件。一般来说,在这个练习中表现最好的模型是全局模型(Gardenia 和 Vakarst),参数数量有限,可以使用自动校准程序进行校准。神经网络模型也显示出相当大的潜力,尽管可用于热身的数据集相对较短(4.5 年),但仍能提供合理的结果。半分布式和全分布式模型也表明,只要付出更多努力,它们就可以表现得很好。使用具有超过 9-12 个校准参数的模型似乎不会提高模型预测的准确性。对预测值和观测值之间的相对误差的评估表明,对于大多数模型,50% 的预测值包含超过 50% 的观测流量差异,25% 的差异大于 100%。大部分预测不佳的值对应于基流,这是令人惊讶的,因为基流通常比峰值流更容易预测。因此,这表明校准的建模方法和标准过于面向水文过程线的峰值流量部分,并且可以通过更多地关注基流来获得改进。大部分预测不佳的值对应于基流,这是令人惊讶的,因为基流通常比峰值流更容易预测。因此,这表明校准的建模方法和标准过于面向水文过程线的峰值流量部分,并且可以通过更多地关注基流来获得改进。大部分预测不佳的值对应于基流,这是令人惊讶的,因为基流通常比峰值流更容易预测。因此,这表明校准的建模方法和标准过于面向水文过程线的峰值流量部分,并且可以通过更多地关注基流来获得改进。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号