Nature Genetics ( IF 31.7 ) Pub Date : 2024-11-15 , DOI: 10.1038/s41588-024-02012-1 N. William Rayner, Young-Chan Park, Christian Fuchsberger, Andrei Barysenka, Eleftheria Zeggini
|
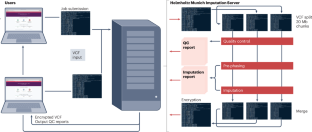
Genomics has the potential to revolutionize healthcare, empowering personalized disease management, including precision prevention. Genome-wide association studies (GWAS) have been instrumental in generating new biological insights into complex human diseases1. The power of GWAS can be increased by increasing sample size through meta-analysis, which requires the imputation and analysis of genotypes that may be untyped across some studies. Imputation relies on the availability of phased haplotype reference panels of whole-genome-sequenced individuals2. These are not amenable to sharing with researchers who need to impute their GWAS data, primarily for reasons of data access and security, dataset size, and scale of computing resources required to enable imputation. Imputation servers have, therefore, been developed to provide a solution: researchers upload their genotyped dataset to the imputation server that hosts the reference panels and imputation machinery, where the data are imputed, and then downloaded back to the researchers’ individual local computing environment. There are a number of imputation servers that serve the global community of researchers, including two based in the USA (University of Michigan, https://imputationserver.sph.umich.edu/index.html and TOPMed, https://imputation.biodatacatalyst.nhlbi.nih.gov/), one based in the UK (Wellcome Sanger Institute, https://imputation.sanger.ac.uk/?about=1) and one based at Kiel University in Germany (https://hybridcomputing.ikmb.uni-kiel.de). Here, we have developed a European Union (EU)-based imputation server serving the community at large, based in Munich, Germany (https://imputationserver.helmholtz-munich.de/), to assist users in complying with their General Data Protection Regulation (GDPR) requirements.
The need for EU-based imputation servers arises from restrictions imposed by GDPR law3, a comprehensive data privacy law in the EU. Genetic data are considered a special category of personal data under GDPR, and hence they are subject to strict data sharing rules and safeguards4. Uploading of genotype data to imputation servers not residing within the EU or covered by an adequacy agreement constitutes a breach of GDPR, unless explicitly covered in informed consent forms for the respective study. Here, we introduce the Helmholtz Munich Imputation Server, designed to provide a cost-free genotype imputation service in a GDPR-compliant manner for EU-based researchers, as well as for researchers globally.
中文翻译:
使用 Helmholtz Munich 基因型插补服务器实现 GDPR 合规性
基因组学有可能彻底改变医疗保健,实现个性化疾病管理,包括精准预防。全基因组关联研究 (GWAS) 有助于为复杂的人类疾病提供新的生物学见解1。可以通过荟萃分析增加样本量来增加 GWAS 的功效,这需要对某些研究中可能未分型的基因型进行插补和分析。插补依赖于全基因组测序个体的阶段性单倍型参考面板的可用性2。这些数据不适合与需要插补其 GWAS 数据的研究人员共享,主要是出于数据访问和安全性、数据集大小以及实现插补所需的计算资源规模的原因。因此,开发了插补服务器来提供一种解决方案:研究人员将他们的基因分型数据集上传到托管参考面板和插补机制的插补服务器,在那里对数据进行插补,然后下载回研究人员的个人本地计算环境。有许多插补服务器为全球研究人员社区提供服务,包括两个位于美国的服务器(https://imputationserver.sph.umich.edu/index.html 年密歇根大学和 TOPMed,https://imputation.biodatacatalyst.nhlbi.nih.gov/ 年),一个位于英国(https://imputation.sanger.ac.uk/?about=1 年惠康桑格研究所)和 https://hybridcomputing.ikmb.uni-kiel.de 年德国基尔大学。在这里,我们开发了一个基于欧盟 (EU) 的插补服务器,为整个社区提供服务,总部位于德国慕尼黑 (https://imputationserver.helmholtz-munich.de/),以帮助用户遵守其《通用数据保护条例》(GDPR) 要求。
对欧盟插补服务器的需求源于 GDPR 法律3 的限制,GDPR 法律是欧盟的一项全面的数据隐私法。根据 GDPR,遗传数据被视为特殊类别的个人数据,因此它们受到严格的数据共享规则和保障措施的约束4。将基因型数据上传到不驻留在欧盟境内或不受充分性协议涵盖的插补服务器构成对 GDPR 的违反,除非在相应研究的知情同意书中明确说明。在这里,我们介绍了亥姆霍兹慕尼黑插补服务器,旨在以符合 GDPR 的方式为欧盟研究人员以及全球研究人员提供免费的基因型插补服务。

















































 京公网安备 11010802027423号
京公网安备 11010802027423号